AI观察笔记第2篇
一、先理解两个基础概念:Token和算力
因为如果你在用的AI工具开始收Token费,就很值得花时间了解一下Token到底是什么?
Token被正式命名为"词元",他是AI大模型处理信息的最小单元——可能是一个字母、一整个词、一个数字等。
• 128K token = 128 × 1,000 = 128,000 个 token
• 1M token = 1 × 1,000,000 = 1,000,000 个 token
比如,"你好,世界" → 可能被分成 3 个 token。高频词更倾向作为一个整体,罕见内容则被拆碎。
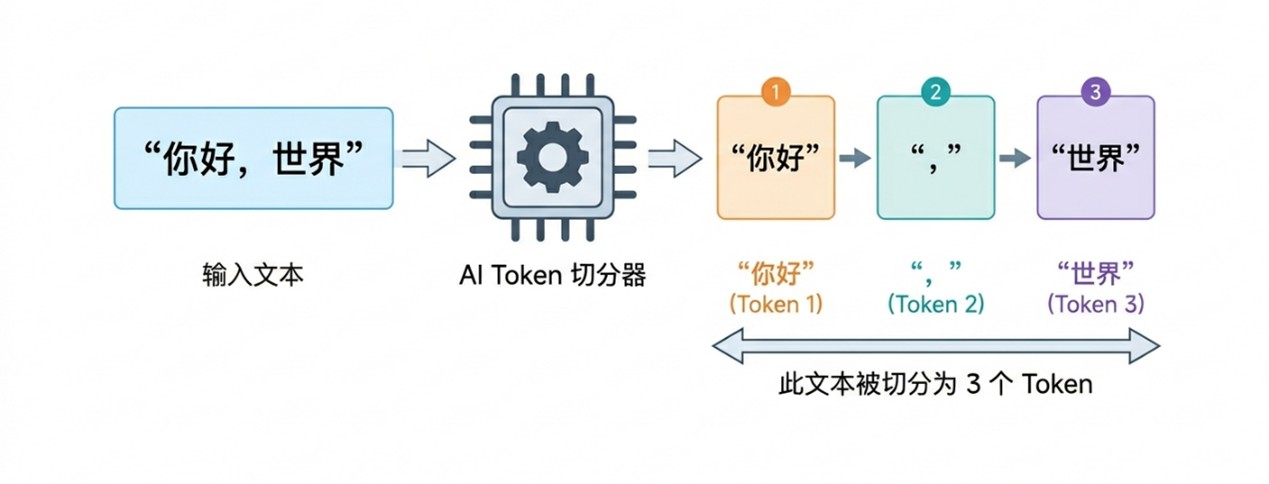
https://mp.weixin.qq.com/s/PTAAinMaXGobU3Yrw_vHkQ
如果说Token是AI处理的信息颗粒,那么算力就是移动与加工这些颗粒所需要的"物理体力"——对应着芯片运转、电能消耗以及冷却系统等。在技术底层,每处理一个 Token,模型都需要完成数十亿次矩阵运算。AI 并非存在于云端的幻象,每一次 Token 的跳动,背后都有真实的能源支出。
据行业通用估算,AI完成一次普通对话约消耗750词元,长文档分析约1.15万词元。截至2026年3月,我国日均Token调用量已突破140万亿,相比2024年初的1,000亿,两年内增长超千倍,背后是海量的算力成本。这也是为什么,近日来多个AI大模型进入了"是否收费"的拐点。
二、我的一些不成熟忧思
现在流行的论调是 "AI替代程序员"。我感觉是低估了"反复烧Token改需求"的长期成本,高估了AI生成代码的可维护性。
程序员写代码和AI写代码,表面上看都是在"生成代码",但底层逻辑完全不同:
| 维度 | 程序员写代码 | AI写代码 |
|---|---|---|
| 思维模式 | 演绎推理:从规则到结论 | 归纳/概率匹配:从模式到猜测 |
| 输入形式 | 编程语言(精确语法) | 自然语言(模糊、多义) |
| 执行过程 | 确定性的:同样的输入 → 同样的输出 | 概率性的:同样的Prompt → 可能不同的输出 |
| 错误方式 | 语法错误/逻辑错误,可精确定位 | "看起来对但其实是错的",难以定位 |
| 修改成本 | 改一行,成本几乎为零 | 改一个需求,可能重新跑整个推理 |
| 可维护性 | 代码即文档,人能理解 | 生成的内容不一定有人能理解 |
| 核心能力 | 精确表达逻辑 | 猜测用户意图 |
初听"自然语言编程"觉得好厉害,但是回归到现时环境中想想,人与人面对面的自然语言理解都存在偏差,现在让AI去精确理解"自然语言",是不是有点儿"强AI所难"了。
一个需要澄清的点
我不是在说"不能用AI写代码"。从0到1,让AI生成很快,但是从1到100的维护迭代过程,AI生成真的比人更省吗?烧Token的成本比人工成本更低吗?
编程语言是确定性的——同样的代码,跑一万次结果都一样。既然它是确定性的,使用者就应该尽量去学习它、掌握它,而不是每次都依赖AI去"猜"。
比如,如果每次遇到同样的HTML问题,都选择写Prompt让AI重新生成,而不是花时间搞懂代码、学会用编辑器直接修改,那效率反而上不去——因为同样的问题你可能要问AI很多次。或许应该让它教你一次怎么改,而不是每次都让他给你改。(感觉表述得还是有些草率了。暂且这样表述吧。)
我感觉在喧嚣的AI浪潮里,需要稳一点儿,更扎实一些,否则,我们可能会在能力退化中失去自己。人机协作的方式需要理性一些——能用确定性逻辑解决的问题,就别交给概率去猜。作为人,不要无意识地放弃自己的大脑。
(写这篇的时候,我本来也想聊聊“算力浪费”与“伪需求”,但一细思,自己的论述还不够完善,逻辑也有些乱,就没硬写。还是得多看看、多积累才行。)
本文仅为个人阶段性思考,观点未必周全。如果你有不同想法,非常欢迎留言交流。